IoT, Big Data und Cloud: 5 wichtige Cloud-Speichertrends, die 2019 kommen
Das Cloud-Computing-Paradigma bietet Unternehmen kostengünstigen Speicherplatz mit hervorragender Zugänglichkeit und unübertroffener Skalierbarkeit. Da der Markt für anwachsen wird $bis 2022 voraussichtlich auf 92 Milliarden, ist klar, dass Unternehmen die Anwendungsfälle dieser Speicherform maximieren wollen.
Dieser Artikel beleuchtet fünf bemerkenswerte Trends im Bereich Cloud-Speicherung, mit besonderem Fokus auf IoT und Big Data, da das Jahr 2019 immer näher rückt.
Cloud, IoTund Big Data
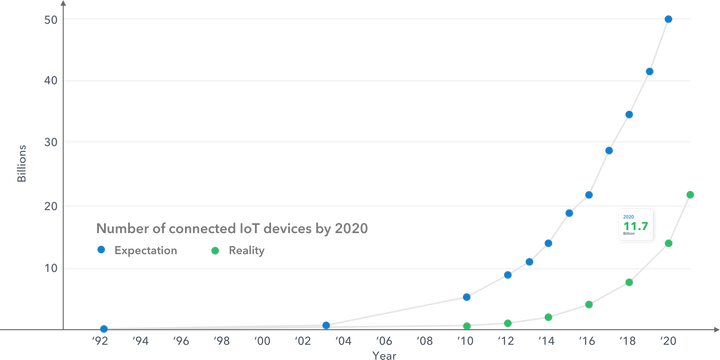
Unternehmen jeder Größe sammeln enorme Mengen komplexer, schnelllebiger Daten, die wertvolle Informationen enthalten und ihnen edge verschaffen oder zu besseren Geschäftsentscheidungen führen können. Ein zunehmender Anteil dieser Daten stammt aus einem Netzwerk intelligenter, mit Sensoren ausgestatteter Geräte – dem sogenannten Internet der Dinge (IoT).
Tatsächlich wird ein so starkes Wachstum der IoT Daten erwartet, dass Cisco schätzt, dass das IoT ab 2019 jährlich mehr als 500 Zettabyte an Daten generieren wird – das sind 500 Millionen Petabyte!
Das Problem besteht darin, dass die Infrastruktur, die zur Verarbeitung, Speicherung und Auswertung von IoT -Daten und anderen Big-Data-Quellen benötigt wird, für den Betrieb vor Ort extrem kostspielig ist. Viele Unternehmen setzen daher auf die Cloud als realistische Alternative für ihre Big-Data-Workloads. Denn die Cloud bietet eine zentrale Plattform mit Zugriff auf leistungsstarke Recheninfrastruktur und kostengünstigen Speicherplatz.
1. Cloud-Big-Data-Analyse
Damit die Cloud Big-Data-Analysen unterstützen kann, muss ihre Architektur den hohen Anforderungen an die Speicherleistung solcher Workloads gerecht werden. Unternehmen, die Big-Data-Analysen in der Cloud durchführen möchten, sollten daher unbedingt auf leistungsstarke, verteilte Speicherlösungen setzen.
Zum Glück erkennen einige der wichtigsten Cloud-Speicheranbieter, darunter AWS, Google und Microsoft, den gestiegenen Bedarf an leistungsfähigerem Speicher und beginnen nun, ihre bestehenden Dienste um die notwendigen Funktionen für die Durchführung von Big-Data-Analysen auf dem gewünschten Leistungsniveau zu erweitern.
Da sich Cloud-Speicheranbieter weiterentwickeln und ihre Dienste verbessern, ist zu erwarten, dass Cloud-Speicher noch stärker zur Unterstützung von Big-Data-Analyse-Workloads eingesetzt wird.
2. Speicherschichtung für Big Data
Auch wenn Unternehmen für die primäre Speicherung großer Datenmengen eine dedizierte Private Cloud oder eine On-Premises-Infrastruktur bevorzugen, können öffentliche Cloud-Speicherdienste in mehrstufigen Speicherkonzepten dennoch eine Rolle spielen. Speicher-Tiering nutzt richtlinienbasierte Datenklassifizierungsregeln, um Daten zwischen verschiedenen Speichertechnologien zu verschieben.
Der Cloud-Storage-Tiering-Service von NetApp kombiniert beispielsweise die Nutzung der leistungsstarken Amazon EBS-Volumes für häufig abgerufene Daten („Hot Data“) mit dem Amazon S3-Objektspeicher für selten abgerufene Daten („Cold Data“). Big-Data-Frameworks wie Hadoop unterstützen diese Art von Storage-Tiering und ermöglichen es Unternehmen, ihre Cluster je nach Zugriffshäufigkeit in Hot- und Cold-Storage-Tiers zu kategorisieren.
Die Speicherung in mehreren Schichten für Big Data bietet eine zusätzliche Kosteneffizienz, insbesondere wenn Unternehmen öffentliche Cloud-Speicherdienste als kostengünstige Option für weniger häufig abgerufene Daten nutzen.
3. Migration dunkler Daten
Laut Gartnerhandelt es sich bei Dark Data um Informationen, die Unternehmen im Rahmen ihrer regulären Geschäftstätigkeit sammeln, aber nicht für andere Zwecke nutzen. Diese Daten könnten wertvoll sein, liegen jedoch in einem unstrukturierten Format vor und sind möglicherweise nicht über eine Abfrage zugänglich (z. B. Informationen in gescannten Dokumenten).
Die Gewinnung ungenutzter Daten wird zunehmen, da Unternehmen versuchen, daraus Nutzen zu ziehen und ihre Analysen durch den Zugriff auf größere Datenmengen zu verbessern. Cloud-Speicherdienste können hierbei hilfreich sein, da sie die Kosten der gesamten Datenextraktion senken.
Idealerweise verwenden Unternehmen Tools zur Extraktion ungenutzter Daten, die in der Lage sind, wertlose Informationen von wertvollen Informationen zu unterscheiden, erstere zu entfernen und letztere in kostengünstigen Cloud-Speicher zu migrieren.
4. Optimierung von Cloud-Speicher für Machine Learning
Die KI-Revolution in Unternehmen ist in vollem Gange, und Cloud-Anbieter verfügen bereits über die notwendigen Technologien, um Unternehmen ihre eigene leistungsstarke KI-Infrastruktur bereitzustellen. Insbesondere Modelle und Algorithmen Machine learning treiben einige der spannendsten Anwendungsfälle von KI in Unternehmen voran.
Da diese Modelle auf große Datenmengen angewiesen sind, um ihre Leistung zu verbessern, ist es nicht verwunderlich, dass Cloud-Anbieter ihre Cloud-Speicheroptionen mit Blick auf machine learning weiter verfeinern und optimieren werden.
5. Speicherung von IoT Sensordaten und App-Entwicklung
Amazon DynamoDB, ein führender Anbieter von Datenspeicherdiensten, IoT stellt latenzarme NoSQL-Datenbanken zum Speichern und Abfragen von Gerätedaten bereit. Gleichzeitig etablieren sich IoT -App-Entwicklung. Sie bieten umfassende Toolsets und App-Komponenten zum Verbinden, Verarbeiten, Speichern und Analysieren von Daten – sowohl am edge als auch in der Cloud. Unternehmen werden diese dedizierten IoT -Speicher- und -Verarbeitungsdienste voraussichtlich 2019 deutlich häufiger nutzen. kleinere, spezialisierte Plattformen wie Ubidots und Losant weiterhin als führende Plattformen für
Einpacken
Cloud-Speicher hat sich seit 1983 rasant weiterentwickelt. Damals bot CompuServe seinen Privatkunden lediglich wenig Speicherplatz für hochgeladene Dateien an. Diese fünf Trends zeigen Ihnen, was Sie 2019 erwarten können, wenn Sie bereits mit Cloud-Lösungen arbeiten oder deren Einführung in Ihrem Unternehmen planen.