Vor- und Nachteile endlicher Automaten: Switch-Case-Anweisungen, C/C++-Zeiger und Nachschlagetabellen (Teil II)
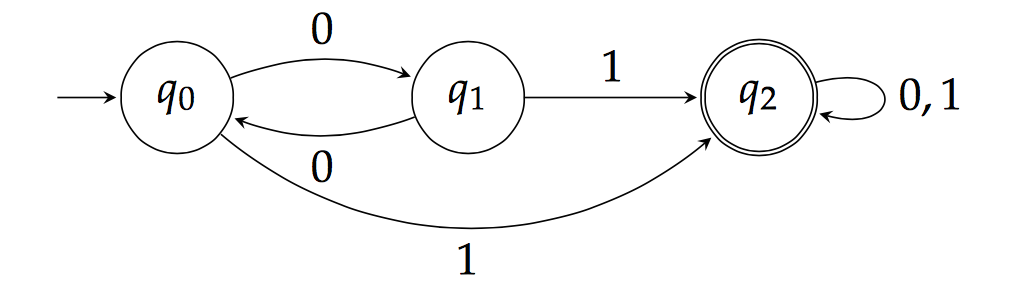
Dies ist der zweite und letzte Teil unserer Implementierung eines endlichen Automaten (FSM). Den ersten Teil der Reihe sowie weitere allgemeine Informationen zu endlichen Automaten finden Sie hier .
Endliche Zustandsautomaten (FSMs) sind im Grunde mathematische Berechnungen von Ursachen und Ereignissen. Basierend auf Zuständen berechnet ein FSM eine Reihe von Ereignissen, abhängig vom Zustand seiner Eingänge. Beispielsweise könnte ein FSM im Zustand „ SENSOR_READ“ ein Relais (auch Steuerungsereignis genannt) auslösen oder eine externe Warnung senden, wenn ein Sensorwert einen Schwellenwert überschreitet. Zustände sind das Fundament des FSM – sie bestimmen sein internes Verhalten und seine Interaktionen mit der Umgebung, wie etwa die Annahme von Eingaben oder die Erzeugung von Ausgaben, die eine Zustandsänderung des Systems bewirken können. Es ist unsere Aufgabe als Hardware-Ingenieure, die passenden FSM-Zustände und auslösenden Ereignisse auszuwählen, um das gewünschte Verhalten zu erzielen, das den Anforderungen unseres Projekts entspricht.
Im ersten Teil dieses Tutorials zu endlichen Zustandsautomaten (FSM) haben wir einen FSM mithilfe der klassischen Switch-Case-Implementierung erstellt. Nun beschäftigen wir uns mit der Erstellung eines FSM mithilfe von C/C++-Zeigern. Dies ermöglicht die Entwicklung robusterer Anwendungen mit einfacherer Firmware-Wartung.
Hinweis : Der in diesem Tutorial verwendete Code wurde 2018 auf dem Arduino Day in Bogotá von José García, einem Ubidots . Die vollständigen Codebeispiele und die Sprechernotizen finden Sie hier .
Nachteile von Switch-Case-Schaltungen:
Im ersten Teil unseres Tutorials zu endlichen Automaten (FSM) haben wir uns mit Switch-Case-Anweisungen und deren Implementierung in einer einfachen Routine beschäftigt. Nun erweitern wir dieses Konzept um „Zeiger“ und zeigen, wie man diese zur Vereinfachung von FSM-Routinen einsetzt.
Eine Switch-Case -Anweisung ähnelt einer If-Else- Anweisung; unsere Firmware durchläuft alle Fälle und prüft, ob die Auslösebedingung erfüllt ist. Betrachten wir im Folgenden ein Beispiel:
switch(state) { case 1: /* Aktionen für Zustand 1 ausführen */ state = 2; break; case 2: /* Aktionen für Zustand 2 ausführen */ state = 3; break; case 3: /* Aktionen für Zustand 3 ausführen */ state = 1; break; default: /* Standardmäßig Aktionen ausführen */ state = 1; }
Im obigen Code finden Sie einen einfachen Zustandsautomaten mit drei Zuständen. In der Endlosschleife prüft die Firmware im ersten Fall, ob die Zustandsvariable gleich eins ist. Ist dies der Fall, wird die zugehörige Routine ausgeführt; andernfalls wird mit Fall 2 fortgefahren und der Zustandswert erneut geprüft. Ist auch Fall 2 nicht erfüllt, wird mit Fall 3 fortgefahren usw., bis entweder der gewünschte Zustand erreicht ist oder alle Fälle abgearbeitet wurden.
switch-case- oder if-else etwas genauer betrachten, um zu sehen, wie wir unsere Firmware-Entwicklung verbessern können.
Angenommen, die Anfangszustandsvariable ist 3: Unsere Firmware muss dann drei verschiedene Wertvalidierungen durchführen. Für einen kleinen Zustandsautomaten mag das kein Problem sein, aber stellen Sie sich eine typische industrielle Produktionsmaschine mit Hunderten oder Tausenden von Zuständen vor. Die Routine muss mehrere unnötige Wertprüfungen durchführen, was letztendlich zu einer ineffizienten Ressourcennutzung führt. Diese Ineffizienz ist unser erster Nachteil – der Mikrocontroller verfügt über begrenzte Ressourcen und wird durch ineffiziente Zustandsautomatenroutinen überlastet. Daher ist es unsere Aufgabe als Ingenieure, so viele Rechenressourcen wie möglich auf dem Mikrocontroller einzusparen.
Stellen Sie sich nun einen endlichen Automaten mit Tausenden von Zuständen vor: Wenn Sie als neuer Entwickler eine Änderung in einem dieser Zustände implementieren müssen, müssen Sie Tausende von Codezeilen in Ihrer Hauptschleife (main loop()) untersuchen. Diese Schleife enthält oft viel Code, der nicht direkt mit dem Automaten zusammenhängt. Daher kann die Fehlersuche schwierig sein, wenn die gesamte Logik des endlichen Automaten in der Hauptschleife konzentriert ist.
Und schließlich ist ein Code mit Tausenden von if-else- oder switch-case -Anweisungen für die Mehrheit der Embedded-Programmierer weder elegant noch lesbar.
C/C++-Zeiger
Schauen wir uns nun an, wie wir einen kompakten endlichen Automaten (FSM) mithilfe von C/C++-Zeigern implementieren können. Ein Zeiger verweist, wie der Name schon sagt, auf eine Stelle im Mikrocontroller. In C/C++ zeigt ein Zeiger auf eine Speicheradresse, um Informationen abzurufen. Mit einem Zeiger kann man während der Ausführung auf den gespeicherten Wert einer Variablen zugreifen, ohne deren Speicheradresse zu kennen. Richtig eingesetzt, bieten Zeiger erhebliche Vorteile für die Struktur Ihrer Routine und vereinfachen die zukünftige Wartung und Bearbeitung.
- Punktcode-Beispiel:
int a = 1462; int myAddressPointer = &a; int myAddressValue = *myAddressPointer;
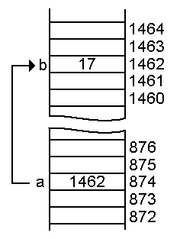
Analysieren wir den obigen Code. Die Variable `myAddressPointer` verweist auf die Speicheradresse der Variable `a` (1462) , während die Variable `myAddressValue` den Wert der von `myAddressPointer` referenzierten Speicheradresse abruft . Demnach liefert `myAddressPointer` und `myAddressValue` Wozu ist das nützlich? Weil wir nicht nur Werte im Speicher ablegen, sondern auch Funktionen und Methodenverhalten. Beispielsweise speichert der Speicherbereich 874 den Wert 1462, kann aber auch Funktionen zur Berechnung der Stromstärke in kA verwalten. Zeiger ermöglichen uns den Zugriff auf diese zusätzliche Funktionalität und die Nutzung von Speicheradressen, ohne dass wir an anderer Stelle im Code eine Funktionsdeklaration verwenden müssen. Ein typischer Funktionszeiger kann wie folgt implementiert werden:
void (*funcPtr) (void);
Können Sie sich vorstellen, dieses Werkzeug in unserem endlichen Automaten (FSM) einzusetzen? Wir können einen dynamischen Zeiger erstellen, der auf die verschiedenen Funktionen oder Zustände unseres FSM verweist, anstatt eine Variable zu verwenden. Mit einer einzigen Variable, die einen sich dynamisch ändernden Zeiger speichert, können wir die Zustände des FSM basierend auf den Eingabebedingungen ändern.
Nachschlagetabellen
Betrachten wir ein weiteres wichtiges Konzept: Lookup-Tabellen (LUTs). LUTs bieten eine geordnete Möglichkeit, Daten in einfachen Strukturen mit vordefinierten Werten zu speichern. Sie sind nützlich, um Daten in unseren FSM-Werten zu speichern.
Der Hauptvorteil von LUTs besteht darin: Bei statischer Deklaration können ihre Werte über Speicheradressen abgerufen werden, was in C/C++ eine sehr effiziente Methode zum Zugriff auf Werte darstellt. Nachfolgend finden Sie eine typische Deklaration für eine FSM-LUT:

void (*const state_table [MAX_STATES][MAX_EVENTS]) (void) = { action_s1_e1, action_s1_e2 }, /* Prozeduren für Zustand { action_s2_e1, action_s2_e2 }, /* Prozeduren für Zustand { action_s3_e1, action_s3_e2 } /* Prozeduren für Zustand };
Das ist viel Stoff zum Nachdenken, aber diese Konzepte spielen eine wichtige Rolle bei der Implementierung unseres neuen und effizienten endlichen Automaten. Jetzt programmieren wir ihn, damit Sie sehen können, wie einfach sich dieser Typ von endlichem Automaten mit der Zeit weiterentwickeln lässt.
Hinweis: Der vollständige Code des FSM ist hier – wir haben ihn der Einfachheit halber in 5 Teile aufgeteilt.
Codierung
Wir erstellen einen einfachen endlichen Automaten (FSM) zur Implementierung einer blinkenden LED. Sie können das Beispiel dann an Ihre Bedürfnisse anpassen. Der FSM hat zwei Zustände: ledAn und ledAus. Die LED schaltet sich jede Sekunde ein und aus. Los geht's!
/* Zustandsautomat-Setup */ /* Gültige Zustände des Zustandsautomaten */ typedef enum { LED_ON, LED_OFF, NUM_STATES } StateType; /* Struktur der Zustandsautomatentabelle */ typedef struct { StateType State; // Funktionszeiger erstellen void (*function)(void); } StateMachineType;
Im ersten Teil implementieren wir unsere LUT zur Zustandserzeugung. Praktischerweise verwenden wir die Methode `enum()`, um den Zuständen die Werte 0 und 1 zuzuweisen. Die maximale Anzahl an Zuständen wird auf 2 gesetzt, was in unserer FSM-Architektur sinnvoll ist. Dieser Typ wird als `StatedType` , damit wir später im Code darauf zugreifen können.
Als Nächstes erstellen wir eine Struktur zum Speichern unserer Zustände. Außerdem deklarieren wir einen Zeiger mit der Bezeichnung ` function` , der als dynamischer Speicherzeiger dient, um die verschiedenen Zustände des endlichen Automaten aufzurufen.
/* Initialer SM-Zustand und Funktionsdeklaration */ StateType SmState = LED_ON; void Sm_LED_ON(); void Sm_LED_OFF(); /* LookUp-Tabelle mit Zuständen und auszuführenden Funktionen */ StateMachineType StateMachine[] = { {LED_ON, Sm_LED_ON}, {LED_OFF, Sm_LED_OFF} };
Hier erstellen wir eine Instanz mit dem Anfangszustand LED_ON, deklarieren unsere beiden Zustände und erstellen schließlich unsere LUT. Zustandsdeklarationen und Verhalten sind in der LUT miteinander verknüpft, sodass wir einfach über int -Indizes . Um beispielsweise die Methode sm_LED_ON() aufzurufen, verwenden wir Code wie StateMachineInstance[0] ;.
/* Benutzerdefinierte Zustandsfunktionen */ void Sm_LED_ON() { // Benutzerdefinierter Funktionscode digitalWrite(LED_BUILTIN, HIGH); delay(1000); // Zum nächsten Zustand wechseln SmState = LED_OFF; } void Sm_LED_OFF() { // Benutzerdefinierter Funktionscode digitalWrite(LED_BUILTIN, LOW); delay(1000); // Zum nächsten Zustand wechseln SmState = LED_ON; }
Im obigen Code ist unsere Methodenlogik implementiert und beinhaltet außer der Aktualisierung der Zustandsnummer am Ende jeder Funktion nichts Besonderes.
/* Hauptfunktionsroutine zur Zustandsänderung */ void Sm_Run(void) { // Stellt sicher, dass der aktuelle Zustand gültig ist if (SmState <NUM_STATES) { (*StateMachine[SmState].function) (); } else { // Fehlercode Serial.println("[ERROR] Ungültiger Zustand"); } }
Die Funktion `Sm_Run()` ist das Herzstück unseres Zustandsautomaten. Beachten Sie, dass wir einen Zeiger (*) , um die Speicherposition der Funktion aus unserer Nachschlagetabelle (LUT) zu extrahieren, da wir während der Ausführung dynamisch auf eine Speicherposition in der LUT zugreifen. ` Sm_Run()` führt stets mehrere Anweisungen, sogenannte Zustandsautomatenereignisse, aus, die bereits an einer Speicheradresse des Mikrocontrollers gespeichert sind.
/* HAUPTFUNKTIONEN DES ARDUINO */ void setup() { // Hier Ihren Setup-Code einfügen, der einmalig ausgeführt wird: pinMode(LED_BUILTIN, OUTPUT); } void loop() { // Hier Ihren Hauptcode einfügen, der wiederholt ausgeführt wird: Sm_Run(); }
Unsere Hauptfunktionen für Arduino sind nun sehr einfach – die Endlosschleife läuft permanent mit der zuvor definierten Zustandsänderungsroutine. Diese Funktion verarbeitet das Ereignis, das den Zustand des endlichen Automaten (FSM) auslöst und aktualisiert.
Schlussfolgerungen
Im zweiten Teil unserer Reihe über endliche Zustandsautomaten und C/C++-Zeiger haben wir die Hauptnachteile von Switch-Case-FSM-Routinen untersucht und Zeiger als geeignete und wünschenswerte Option identifiziert, um Speicherplatz zu sparen und die Funktionalität des Mikrocontrollers zu erhöhen.
Zusammenfassend hier einige Vor- und Nachteile der Verwendung von Zeigern in Ihrer Finite-State-Machine-Routine:
Vorteile:
- Um weitere Zustände hinzuzufügen, deklarieren Sie einfach die neue Übergangsmethode und aktualisieren Sie die Nachschlagetabelle; die Hauptfunktion bleibt unverändert.
- Sie müssen nicht jede if-else-Anweisung ausführen – der Zeiger ermöglicht es der Firmware, zu dem gewünschten Befehlssatz im Speicher des Mikrocontrollers zu springen.
- Dies ist eine prägnante und professionelle Methode zur Implementierung von FSM.
Nachteile:
- Sie benötigen mehr statischen Speicher, um die Nachschlagetabelle zu speichern, in der die FSM-Ereignisse gespeichert sind.
